
Someone runs a query.
One of those obnoxious ones…which scans a billion rows, scattered across a dataset large enough to have its own gravitational pull, all to find, say, ten records. Something highly specific, highly selective—the kind of query that usually requires patience and a cluster running hotter than anyone’s comfortable with.
But it returns in under a second.
And the cluster doesn’t buckle. No new workers spin up. No runaway resource allocation. Just ten clean rows, piped back through the interface with no drama.
At first, the assumption is caching. Wait, no, precomputation? Cheating? But it’s none of those.
What’s happening underneath is weirder than optimization. It’s an architectural shift. An infrastructure layer that doesn’t distinguish between objects and rows, between structured and unstructured, between ingestion and analysis.
It’s a system that wasn’t built to be a database in the traditional sense—and so it sidestepped most of the traditional bottlenecks by never internalizing them in the first place.
VAST DataBase didn’t arrive as a feature. It emerged as a consequence. And even more interesting? The database didn’t land on the platform. The platform just absorbed the database.
The Old World Was Bifurcated by Design
There’s a reason transactional and analytical systems were always split and that reason wasn’t ideological—it was physical.
Row-oriented systems like Postgres, MySQL, Oracle and the ilk exist to get records written fast.
They lean heavily on intent logs and write ahead logs (WALs) to provide A-tomicity and D-durability, as they are a necessity for an ACID database, and appending to files has been historically the fastest way to do this. They index lightly and buffer intelligently. They trade deep introspection for latency and concurrency. Analytical systems, meanwhile, are built for depth. They ingest in batches, optimize storage layouts, and scan aggressively. They’re columnar because they must be: every scan a rifle shot across a petabyte landscape.
Even in the “cloud-native” reimagining (e.g. Snowflake, BigQuery, Delta Lake, Iceberg) the distinction holds but it’s just submerged under more layers. Insert performance is still so-so. Query performance is only tolerable if you’ve partitioned perfectly, or if you over-provision. Everything’s optimized around immutable objects—hundreds of thousands if not millions, each one a tiny speed bump for object storage and the compute engines sitting above it.
So you do what everyone does: You separate your worlds. Ingest here, analyze there. A database for the now, a warehouse for the later, and a lot of fragile ductwork in between. It works, mostly. Until scale makes the inefficiencies too expensive to ignore.
But What About Infrastructure That Doesn’t Care What Shape Your Data Is?
What VAST built, and did so long before it ever called anything a “database” per se, was infrastructure that handled data on its own terms.
Not tables, not files. Just data.
Its Element Store architecture wasn’t optimized for SQL. It was optimized for atomic persistence, for big metadata throughput, for tracking and migrating everything from files to records to objects across storage-class memory and QLC flash. Its I/O path wasn’t grafted onto an external store; it was vertically integrated across the entire data lifecycle.
So when VAST DB appeared, it didn’t look like a database being introduced to an infrastructure platform. It looked like structured data finally being accepted as native.
And that changed everything.
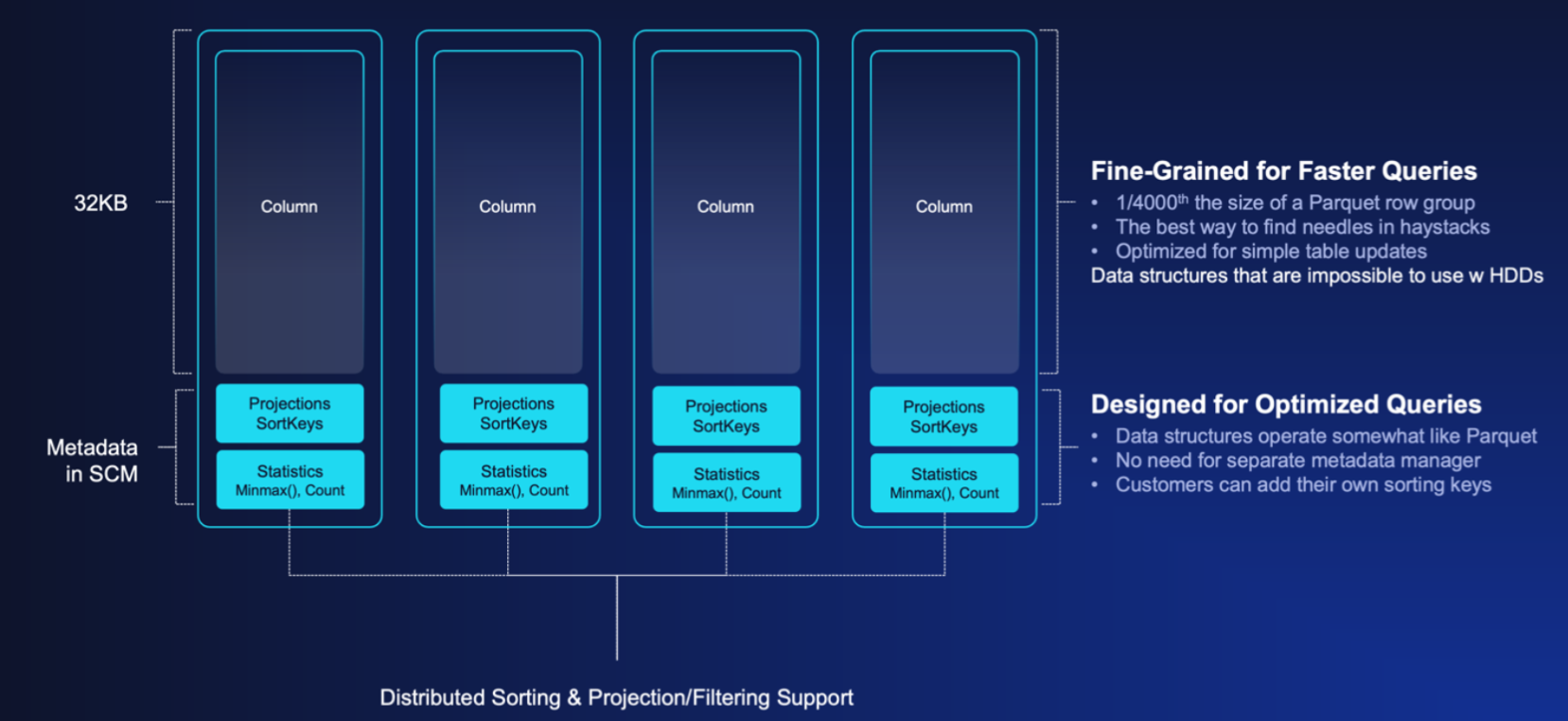
In this new world, records don’t land in some temporary buffer. They’re immediately written to persistent, stable storage in a column oriented layout, as opposed to rows that need restructuring later. They go in clean, stripe-aligned, and query-ready. Each extent is ~32KB on average. Small enough for high-performance ingestion. Large enough for analytical scans.
Later, those extents are migrated to flash, coalesced with other data but never rewritten, never copied into a different shape. That write-once-read-many trick applies whether the original input was a 300GB model checkpoint, or a 14-column transactional row.
There is no distinction, it’s all just data, managed by the same system, governed by the same metadata plane.
But Here’s Where Most Systems Break...
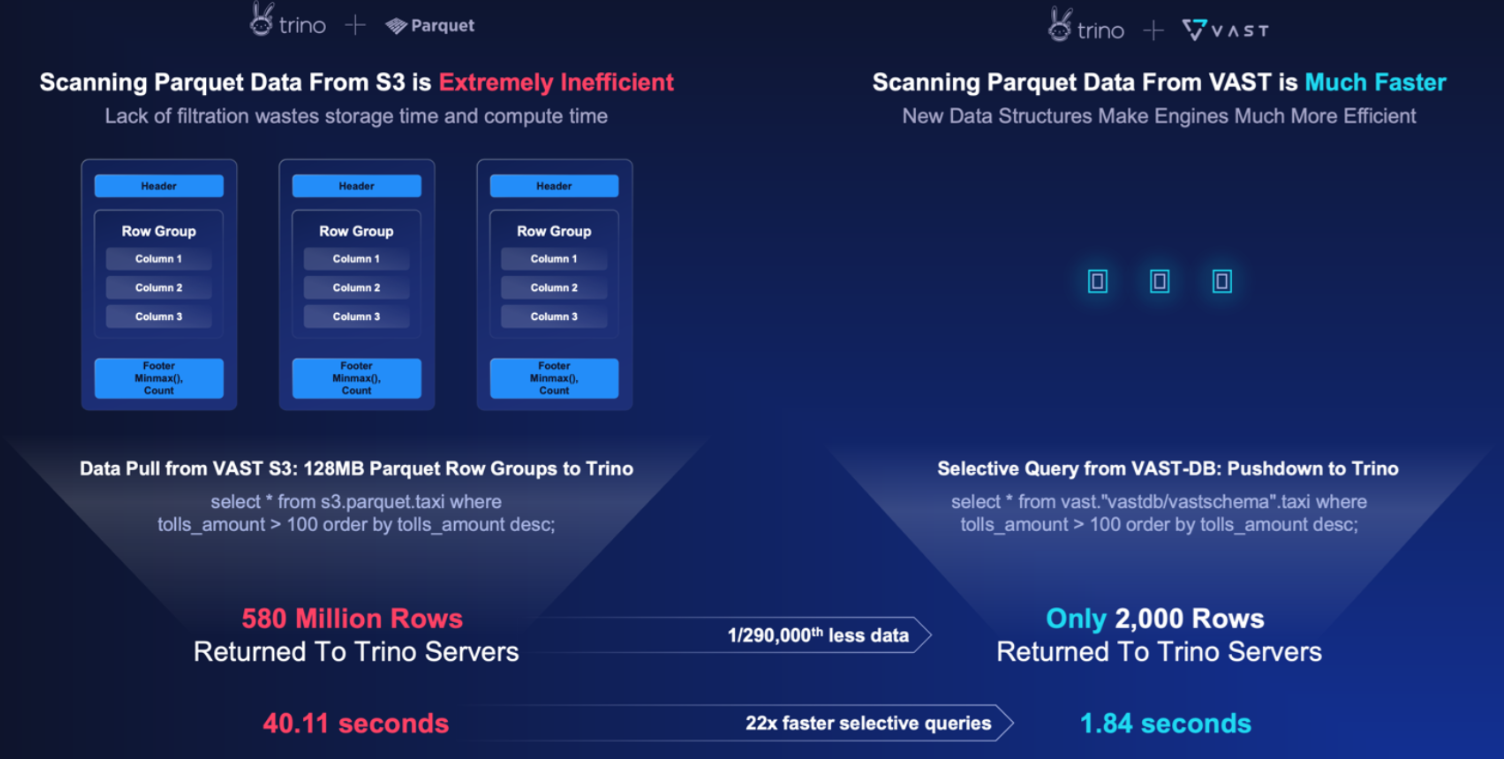
To understand why this matters, let’s go back to that query. One billion rows. Ten matches. A needle-in-haystack scenario.
On Parquet or ORC—on Iceberg or Delta Lake—you’re reading MBs or GBs just to filter 99.9% of it away. Even with partition pruning. Even with caching. The engine reads, deserializes, filters, and discards. What that ultimately means is that your CPUs are busy, your memory’s overcommitted, and your I/O bill just went up. Again.
And even then, the result takes seconds.
With VAST DataBase, that query pushes down its predicate—its filter—into the database itself. The Element Store resolves which extents matter and which don’t. So the engine only touches the blocks it needs. There is no overscan. There is no post-filtering in memory. The infrastructure does it before the query engine ever sees a byte.
That’s not an optimization. That’s a redefinition of the query boundary. And the meaty thing here is that you’re not accelerating Trino or Spark. You’re shrinking them.
Because with predicate pushdown that actually works, and ingestion that doesn’t create I/O bottlenecks, the compute layer gets dramatically smaller. Fewer nodes. Less memory. Less ephemeral cache management and fewer retries.
At the end of the day that that means is that what used to take a ten-node cluster can now run on three. What used to cost you $2,000/month to run 24/7 costs $400, or less in this hypothetical scenario.
Speed is nice. Cost is nicer. Both? Chef’s kiss.
Not to Bore You With Transactional Insert Performance But….
You probably know that columnar systems aren’t supposed to be good at inserts. That’s the rule. That’s why you buffer and batch. That’s why you write append-only logs and hope you can compact later without melting your IOPS budget.
But VAST DataBase handles ingestion the same way it handles file writes: atomic, immediately visible, and formatted for future scans.
There’s no fake row-first staging layer. No second system for write optimization. You can insert, kid you not, millions of records per second, in native columnar layout, with no post-processing required.
If you’ve ever tried to insert records into Iceberg in real time, you already know the experience: low throughput, immutable file churn, constant rewrites, and an eventual showdown with your cloud provider over the number of PUTs per hour.
Here, ingestion just works. Structured data is no longer a special case.
The Collapse of Complexity
What VAST DB represents isn’t the arrival of another database on the scene. It’s the disappearance of the artificial boundary between ingestion and insight.
Historically, that boundary made sense. Columnar was slow to write, fast to read. Row-based was the opposite. So we built two stacks. And then we built pipelines to connect them. And then we built orchestration layers to manage the pipelines. And then we built observability tools to manage the orchestration.
All of that—every tool, every script, every cloud bill bloated by unnecessary handoffs—was an expression of architectural deficiency.
VAST DB removes the need for all of it. Not because it reimagined the database. But because the infrastructure underneath it never learned to draw those lines in the first place.
It treats structured and unstructured data the same. It stores it the same. It moves it the same. It indexes it with the same metadata engine. It migrates it across the same flash tiers, the same protection schemes, the same atomic workflows.
There is no handoff. There is no translation layer. There is just data. Inserted, queried, managed.
Wait, Does This Mean You Don’t Need Two Systems?
The modern data stack has been lying to itself for a while.
It tells a story of flexibility, openness, modularity. But underneath that story is a hard truth: you can’t patch over fundamental limitations forever. At some point though, the physics break through. At some point, you have to stop layering and start redesigning.
That’s what happened here—not a new product line, but a collapse of unnecessary layers.
VAST DB isn’t a “database product.” It’s an expression of a deeper design principle:
If your infrastructure doesn’t care what shape your data is, your software doesn’t have to either.