
For most of the history of AI development, it was assumed that the limiting factor would be hardware. Compute was the most visible bottleneck: GPUs, memory bandwidth, the energy required to power sprawling datacenters.
This assumption made sense. Infrastructure problems have a solidity to them. They can be measured, priced, and optimized and for every constraint, there was an engineer ready to propose a path.
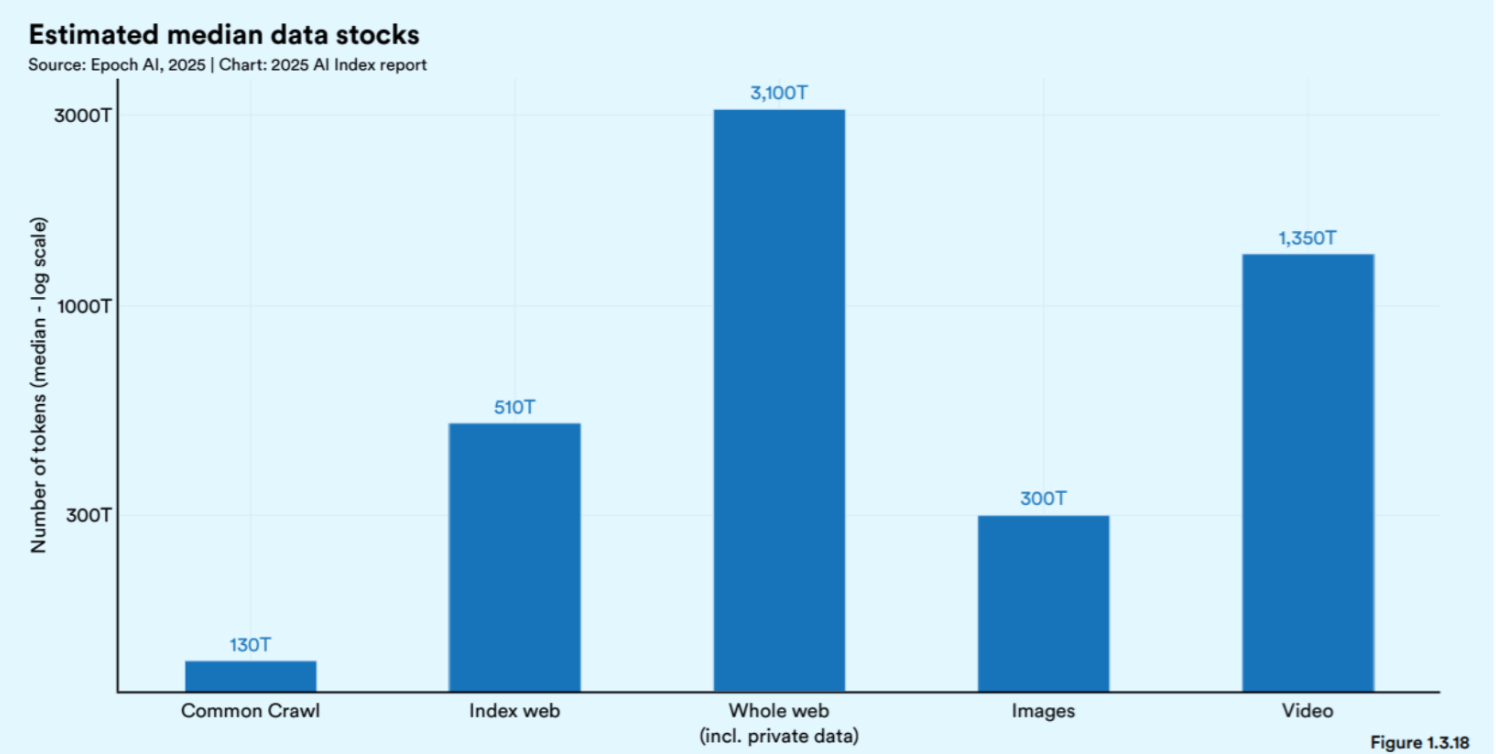
But we now find ourselves in an unexpected bind and even for those with the foresight to see it coming, it probably wasn’t expected so soon. We’ve almost exhausted the corpus of material generated by the whole of civilization. All of this, the sum total of the world’s brilliance, amounts to something on the order of 300 trillion tokens.
Does that sound like a lot when you set it against the consumption patterns of modern large language models, trained on billions of tokens per day?
Through that lens, the awe and scale begins to invert. The great abundance is suddenly finite, and alarmingly so.
As part of the much larger discussion on data constraints for large-scale model training, the Stanford-led AI Index cites findings from a study conducted by researchers affiliated with Epoch AI, a nonprofit organization focused on empirical AI forecasting.
The report, "Will We Run Out of Data?," projects that available high-quality human-generated text could be depleted between 2026 and 2032, depending on model training strategies.
This highlight section from Epoch forces a more uncomfortable realization: that the ultimate limit to scaling may not be hardware at all, but data, not in the abstract sense but in the much more immediate and mundane sense that the world simply does not contain an infinite supply of human-generated, high-quality text for models to learn from.
Under current growth rates, and assuming training practices remain roughly compute-optimal, Epoch projects that the world's stock of high-quality training data will be exhausted sometime between 2026 and 2032.
That is the generous view. In reality, the economic dynamics of model deployment favor overtraining — feeding models significantly more data during training than would be strictly efficient, because the cost savings realized during inference justify the initial expense.
With a relatively modest 5× overtraining factor, the exhaustion timeline collapses to 2027.
(Source)
If more aggressive strategies are pursued — and in a landscape increasingly dominated by arms-race incentives, they almost certainly will be — the data could be gone as early as 2025.
The industry will not stop scaling simply because the human corpus runs dry. Instead, it will turn inward.
The solution, already visible in research pipelines, is synthetic data: text generated by models themselves, refined, filtered, and reintroduced as new training material.
On paper, synthetic generation promises to solve the scarcity problem. If models can create their own examples, the available supply of training data becomes, in theory, limitless. Scaling can continue without waiting for humanity to produce more raw material.
But synthetic data is not a neutral replacement. It is an echo, not an extension. We can expect it will inherit the biases, blind spots, and statistical regularities of the models that created them.
No matter how elaborate the filtering pipelines become, or how adversarial the training loops are tuned, synthetic data cannot recreate the unpredictable richness of real human expression.
It cannot invent new genres of error. Put quite simply, it cannot surprise itself.
Over time, as models are trained on data generated by slightly earlier versions of themselves, a subtle form of drift sets in. Language becomes cleaner, more predictable, less anchored to the messy and contradictory substrate of lived human experience.
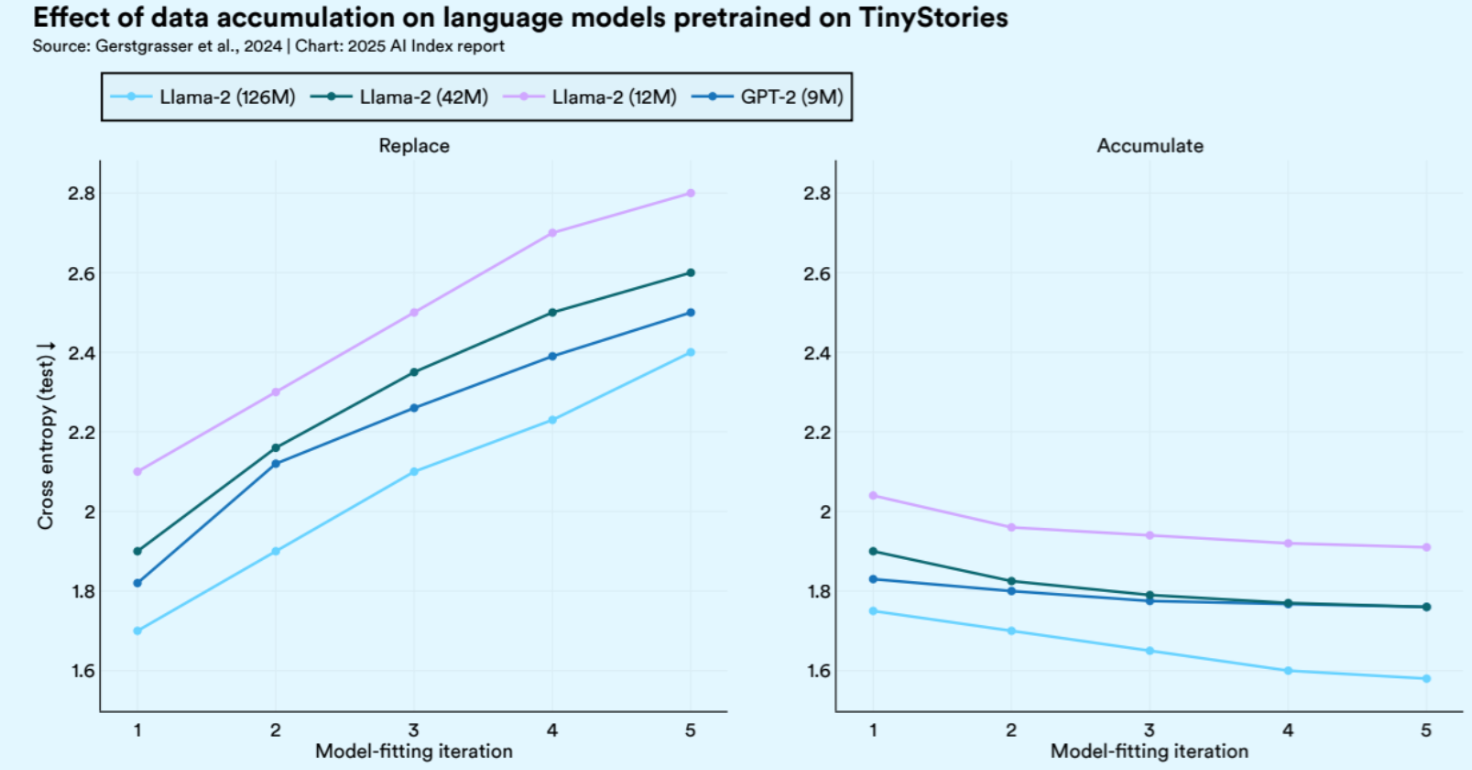
Reusing data causes overfitting—raising concerns for synthetic training. Models trained repeatedly on the same data ("Replace") show worsening performance, while performance improves with new data ("Accumulate"), highlighting risks in relying heavily on synthetic data without true novelty.
In short, and without being dramatic, the world that the models "understand" gradually diverges from the world that actually exists.
But aren’t there workarounds for that? Well, to a point.
Weighting synthetic and human data differently, introducing noise, employing adversarial refinement — will buy us some time. But that can do little to reverse the underlying dynamic.
The training data will become increasingly self-referential. The systems will continue to grow in size and apparent fluency, but their relationship to external reality will thin.
The models will not stop improving by the metrics we currently measure: loss curves will flatten, benchmark scores will rise. But beneath the surface, something essential will have shifted.
We will have crossed from a phase where machine learning was an act of discovery, extracting latent structures from human knowledge, into a phase where it becomes an act of self-replication, models learning from mirrors of themselves, forgetting without even knowing that anything has been forgotten.
The subreport does not issue warnings or prescriptions. It does not traffic in melodrama. It simply lays out the numbers, and lets the consequences unfold.
But if you read carefully, the message is clear: There is still time to change course. If we continue as we are, treating scaling as the only goal, and data as a problem to be solved rather than a foundation to be honored, then the future of intelligence will not be a grand flowering, it will be a closing loop.